从MySQL数据库phx中读取tree表到HDFS
执行命令:1
sqoop import --connect jdbc:mysql://node1:3306/phx \--username root --table tree --m 1
命令行输出:
1 | Warning: /csh/link/sqoop/../hcatalog does not exist! HCatalog jobs will fail. |
访问 http://node1:8088 可以看到生成一个MapReduce任务
结果: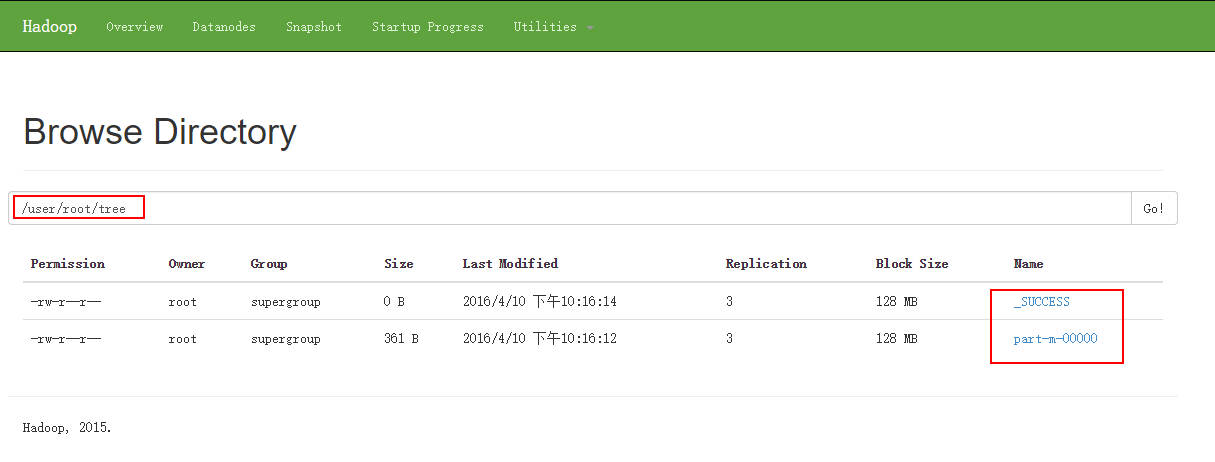
1 | [root@node1 sbin]# hadoop fs -cat /user/root/tree/p* |
导入到指定目录
参数:1
--target-dir /directory
例如:1
sqoop import --connect jdbc:mysql://node1:3306/phx \--username root --table tree --m 1 \--target-dir /sqoop/
结果: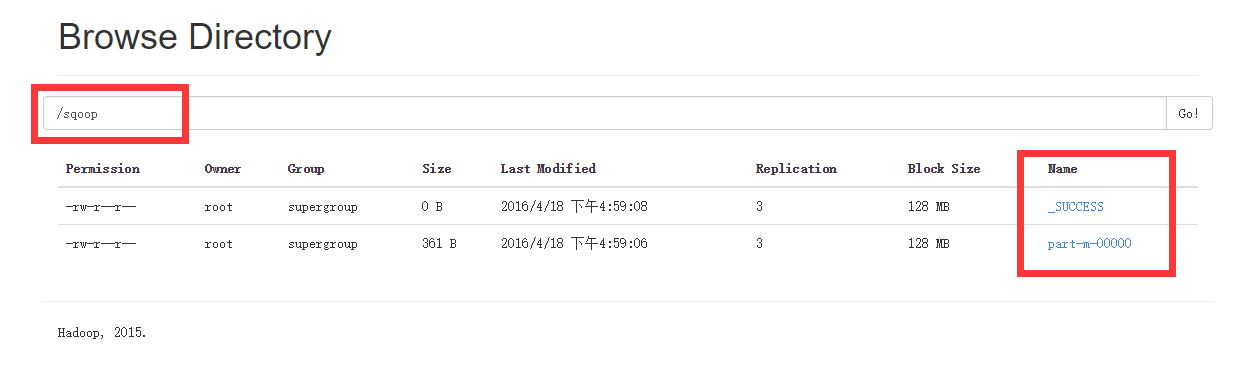
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21[root@node1 sbin]# hadoop fs -cat /sqoop/p*
1,466464684640,1
2,466464684641,2
3,466464684642,3
4,466464684643,1
5,466464684644,2
6,466464684645,3
7,466464684646,1
8,466464684647,2
9,466464684648,3
10,466464684649,1
11,4664646846410,2
12,4664646846411,3
13,4664646846412,1
14,4664646846413,2
15,4664646846414,3
16,4664646846415,1
17,4664646846416,2
18,4664646846417,3
19,4664646846418,1
20,4664646846419,2
导入表子集
参数:1
--where <condition>
例如:1
sqoop import --connect jdbc:mysql://node1:3306/phx \--username root --table tree --m 1 \--where "productinformationId"='1' \--target-dir /sqoop/tree2/
结果: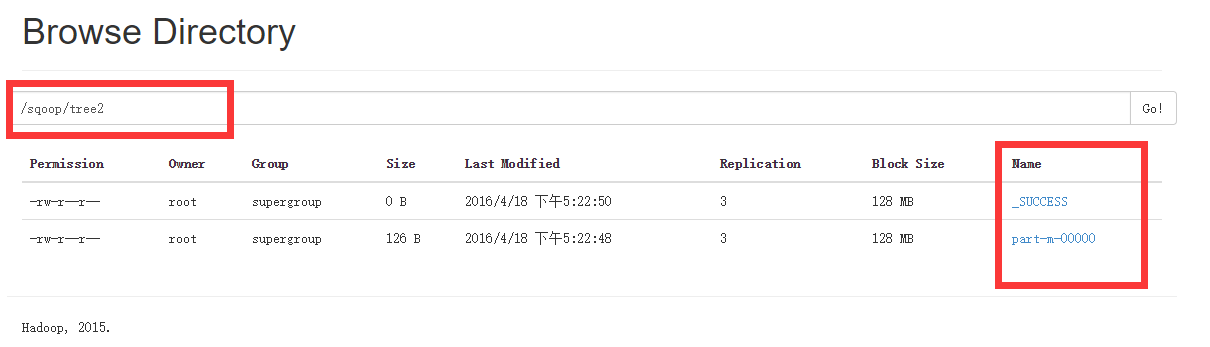
1 | [root@node1 sbin]# hadoop fs -cat /sqoop/tree2/p* |
增量导入(即只导入新添加的那部分数据)
参数:
1 | --incremental <mode> 选择模式,有:append 和 lastmodified |
例如:
在数据库表tree中添加一条记录,如下图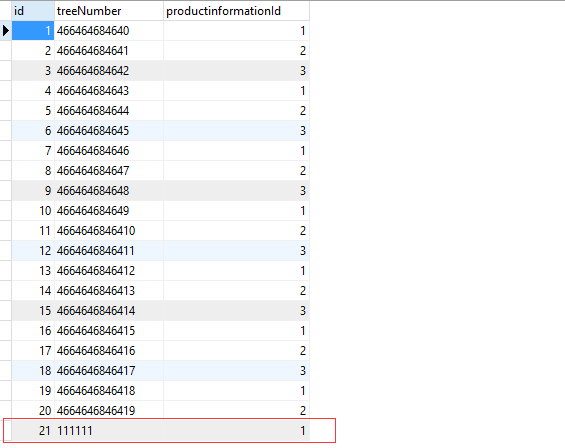
运行命令:
1 | sqoop import --connect jdbc:mysql://node1:3306/phx \--username root --table tree --m 1 \--target-dir /sqoop/ \--incremental append \--check-column id \--last-value 20 |
结果: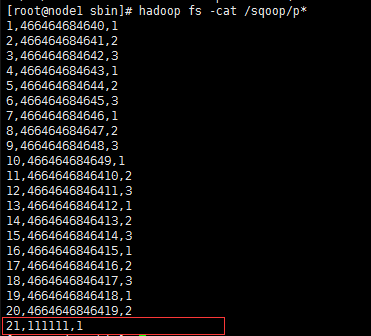
参数列表
| 参数 | 说明 |
|---|---|
| –append | 将数据追加到hdfs中已经存在的dataset中。使用该参数,sqoop将把数据先导入到一个临时目录中,然后重新给文件命名到一个正式的目录中,以避免和该目录中已存在的文件重名。 |
| –as-avrodatafile | 将数据导入到一个Avro数据文件中 |
| –as-sequencefile | 将数据导入到一个sequence文件中 |
| –as-textfile | 将数据导入到一个普通文本文件中,生成该文本文件后,可以在hive中通过sql语句查询出结果。 |
| –boundary-query |
边界查询,也就是在导入前先通过SQL查询得到一个结果集,然后导入的数据就是该结果集内的数据,格式如:–boundary-query ‘select id,no from t where id = 3’,表示导入的数据为id=3的记录,或者 select min( |
| –columns |
指定要导入的字段值,格式如:–columns id,username |
| –direct | 直接导入模式,使用的是关系数据库自带的导入导出工具。官网上是说这样导入会更快 |
| –direct-split-size | 在使用上面direct直接导入的基础上,对导入的流按字节数分块,特别是使用直连模式从PostgreSQL导入数据的时候,可以将一个到达设定大小的文件分为几个独立的文件。 |
| –inline-lob-limit | 设定大对象数据类型的最大值 |
| -m,–num-mappers | 启动N个map来并行导入数据,默认是4个,最好不要将数字设置为高于集群的节点数 |
| –query,-e |
从查询结果中导入数据,该参数使用时必须指定–target-dir、–hive-table,在查询语句中一定要有where条件且在where条件中需要包含 \$CONDITIONS,示例:–query ‘select * from t where \$CONDITIONS ‘ –target-dir /tmp/t –hive-table t |
| –split-by |
表的列名,用来切分工作单元,一般后面跟主键ID |
| –table |
关系数据库表名,数据从该表中获取 |
| –delete-target-dir | 删除目标目录 |
| –target-dir |
指定hdfs路径 |
| –warehouse-dir |
与 –target-dir 不能同时使用,指定数据导入的存放目录,适用于hdfs导入,不适合导入hive目录 |
| –where | 从关系数据库导入数据时的查询条件,示例:–where “id = 2” |
| -z,–compress | 压缩参数,默认情况下数据是没被压缩的,通过该参数可以使用gzip压缩算法对数据进行压缩,适用于SequenceFile, text文本文件, 和Avro文件 |
| –compression-codec | Hadoop压缩编码,默认是gzip |
| –null-string |
可选参数,如果没有指定,则字符串null将被使用 |
| –null-non-string |
可选参数,如果没有指定,则字符串null将被使用 |